Introdução:
Quem já esta atuando com inteligência artificial desde 2022 sabe que por muito tempo (e ate hoje) o contexto e pergunta fornecido a IA é extremamente importante, principalmente em grandes contextos como chatbot corporativos, multiagentes e fluxos complexos de automação, qual quer virgula, letra maiúscula, mudança de palavra que para nós é meramente igual pode quebrar toda a performance e confiabilidade final.
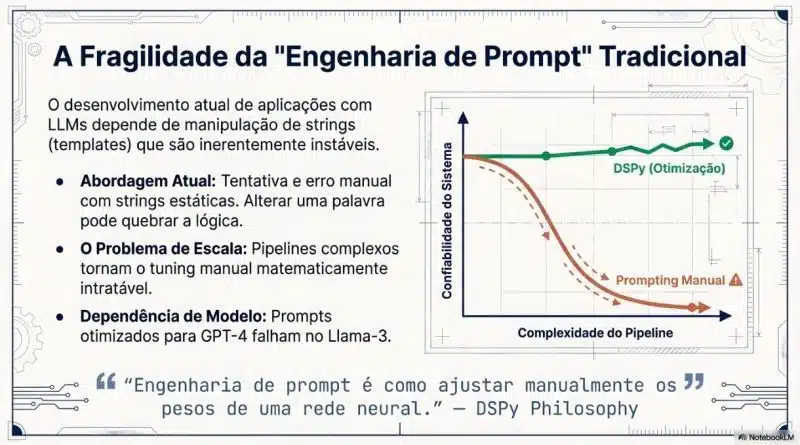
Passamos para a fase de se aprofundar em prompt com a tal da “engenharia de prompt” que inclusive a Anthropic lançou seu curso gratuito que na tradução seria algo como Fluência em prompt (https://www.anthropic.com/learn/claude-for-you) eu mesmo terminei o curso e percebi o quão complexo e bem estruturado deve ser os contextos para nossos agentes e suas instruções. Recentemente a mais ou menos 3 semanas venho estudando um framework em python chamado Dspy que tem como principal objetivo abstrair essa complexidade mudando para uma abordagem de programação modular e não de forma manual com prompts.
OBS: Ao final vou disponibilizar um projeto completo funcional no github
Como surgiu o Dspy:
Ele foi desenvolvido por alunos De Stanford (pra variar rsrsrs) de forma modular, ou seja, você tem assinaturas (que são uma espécie de contratos), módulos que são a forma algoritmia de definir qual tipo de estratégia de raciocinou será utilizado, como CoT (Chain Of Thought), few-shot, ReAct que é basicamente raciocinar e agir entrou outros. Portanto o Dspy surgiu para resolver a fragilidade e a falta de escalabilidade referente ao prompt engineer manual, mas mais na frente vai ficar muito claro.
Motivadores para se utilizar o Despy:
1° Inadequação do “Prompt Engineering”:
Os fundadores notaram que o desenvolvimento de aplicações de IA era baseado em tentativas A/B até acertar o prompt e descobriram strings estáticas e frágeis, com o Despy você definir a entrada e a saída e ele se encarrega de encontrar o melhor prompt e salvar.
2° Portabilidade entre Modelos:
Um prompt otimizado pelo Dspy pode mudar facilmente entre modelos, seja GPT, Gemini, Kimi etc.. Isso por que o Dspy aprende novamente o melhor prompt para seu cenário e modelo.
3° Programabilidade:
Transformar o design de sistemas de IA em algo próximo da engenharia de software onde grandes frameworks como Langchain, Crew.AI e SDKs são próximos a engenharia de software isso deixa mais suave e familiar.
4° Auto-refinamento:
O modelo recebe uma nova chance de gerar a saída, agora ciente do erro anterior e das instruções de correção, transformando a inferência em um processo de “autocura”.
Em resumo, o DSPy nasceu da pergunta: “Podemos projetar programas de LLM que aprendam a se aprimorar sozinhos em vez de reescrevermos prompts manualmente”.
Conceitos principais do Dspy:
Signatures:
Declaram a tarefa (entrada/saídas) sem especificar como o modelo deve realizá-la.
from dspy import ReAct
class QAWithReAct(dspy.Signature):
"""Responder perguntas usando ferramentas externas quando necessário."""
question: str = dspy.InputField()
answer: str = dspy.OutputField(desc="Resposta final para o usuário")Modules:
Define a estratégia que são blocos de construção reutilizáveis que encapsulam técnicas de raciocínio como ‘ChainOfThought’ e ‘ReAct’.
class CoTSentimentClassifier(dspy.Module):
def __init__(self):
super().__init__()
self.cot = dspy.ChainOfThought(SentimentSignature)
def forward(self, sentence: str) -> dspy.Prediction:
# O LM é induzido a "pensar passo a passo" antes de dar o rótulo.
return self.cot(sentence=sentence)
Optimizers:
A Otimização são algoritmos que ajustam automaticamente os prompts para maximizar uma métrica de avaliação definida pelo usuário:
# Otimizador
optimzer = dspy.BootstrapFewShot(
metric=sentiment_accuracy,
max_bootstrapped_demos=4
)
Essa estrutura aumenta drasticamente a precisão em tarefas complexas, como problemas matemáticos.
DSPy, a coleta de dados
Esta é a base que permite a transição do ajuste manual de prompts para a otimização sistemática. Diferente do treinamento tradicional de deep learning que exige milhares de registros, o DSPy é projetado para funcionar com conjuntos de dados muito pequenos, muitas vezes necessitando de apenas 5 a 10 exemplos para começar a gerar resultados robustos.
1. A Unidade Básica: dspy.Example
Toda a estrutura de dados no framework gira em torno do objeto dspy.Example. Ele funciona como um dicionário Python especializado que armazena os campos de entrada e as saídas esperadas para o seu programa.
2. Definição de Entradas com .with_inputs()
Ao coletar seus dados, você deve informar explicitamente ao framework quais campos são as entradas da tarefa utilizando o método .with_inputs(). Isso é crucial para que os otimizadores saibam quais informações estarão disponíveis para o modelo no momento da inferência e quais devem ser geradas ou aprendidas.
Por exemplo:
def _format_for_dspy(self, df: pd.DataFrame) -> list[Example]:
"""Formats a DataFrame into a list of dspy.Example objects."""
formatted_examples = []
for _, row in tqdm(df.iterrows(), total=df.shape[0], desc="Formatting examples"):
example = Example(
text=row['text'],
sentiment=row['sentiment']
).with_inputs("text")
formatted_examples.append(example)
return formatted_examples
3. Dados Não Rotulados e Bootstrapping:
Uma das maiores vantagens do DSPy é a capacidade de trabalhar com dados incompletos ou sem rótulos. Se você possuir apenas as perguntas (inputs), o compilador pode utilizar um modelo de linguagem mais forte (como o GPT-4o) atuando como um “professor” para gerar automaticamente as cadeias de raciocínio e respostas corretas (traços) durante o processo de bootstrapping. Esses traços bem-sucedidos tornam-se, então, o conjunto de treinamento para otimizar modelos menores ou mais eficientes. Da hora não?
Para quem não entendeu essa questão de “professor” e bootstraping deixa eu simplificar:
DSPy permite otimizar programas de IA sem precisar de dados prontos com respostas. Vou quebrar isso em partes simples. Normalmente, para treinar IA você precisa de:
Pergunta: "Qual a capital da França?" → Resposta: "Paris"
Pergunta: "2+2=?" → Resposta: "4"
Mas e se você só tem as perguntas? Sem respostas prontas.
Como o DSPy Resolve (Bootstrapping)
1. Você dá só as perguntas
perguntas = [
"Qual a capital da França?",
"Quanto é 2+2?",
"Explique gravidade"
]
2. DSPy usa um “Professor” (LM forte)
- Configura GPT-4o (ou Gemini Pro) como teacher_settings
- Esse professor inventa as respostas + raciocínio:
Pergunta: "Qual a capital da França?"
Professor GPT-4o gera:
→ Raciocínio: "França é um país europeu..."
→ Resposta: "Paris"
3. Gera “traços” automáticos
Traço 1: pergunta → [raciocínio] → Paris ✓ (funciona bem)
Traço 2: pergunta → [raciocínio ruim] → Londres ✗ (descarta)
Traço 3: pergunta → [raciocínio] → Paris ✓ (guarda)
4. Filtra os “bons traços”
DSPy testa cada traço gerado:
- Funcionou? → Guarda como “few-shot example”
- Falhou? → Descarta
5. Um código simples na prática:
# 1. Só perguntas (sem respostas)
trainset = [{"question": "Capital da França?"} for _ in range(20)]
# 2. Professor GPT-4o gera respostas
teleprompter = BootstrapFewShot(metric=validate_qa) # usa GPT-4o como teacher
# 3. Otimiza Llama3.2 local
compiled = teleprompter.compile(program, trainset=trainset)
3. Configuração e Flexibilidade de Modelos:
Independência de Modelo: Capacidade de alternar entre APIs remotas (OpenAI, Anthropic) e modelos locais via Ollama ou SGLang.
Configuração Centralizada: Uso do dspy.settings.configure para gerenciar LMs e modelos de recuperação (RM) globalmente
DSPy permite trocar modelos de IA com 1 linha de código. Não importa se é OpenAI, local ou Google.
1. Independência de Modelo (Plug & Play)
Mesma lógica, LMs diferentes:
# Seu programa DSPy (igual sempre)
classifier = SentimentClassifier()
# === OPÇÃO 1: OpenAI caro (produção) ===
lm_openai = dspy.OpenAI(model='gpt-4o-mini')
dspy.settings.configure(lm=lm_openai)
result1 = classifier("Gostei muito!") # Usa GPT-4o-mini
# === OPÇÃO 2: Modelo LOCAL grátis (teste) ===
lm_local = dspy.OllamaLocal(model='llama3.2:1b', base_url='http://localhost:11434')
dspy.settings.configure(lm=lm_local)
result2 = classifier("Gostei muito!") # Usa Llama LOCAL
# === OPÇÃO 3: Google Gemini (rápido/barato) ===
lm_gemini = dspy.Google(model='gemini-1.5-flash')
dspy.settings.configure(lm=lm_gemini)
result3 = classifier("Gostei muito!") # Usa Gemini
Resultado: result1.sentiment, result2.sentiment, result3.sentiment usam o MESMO código, só mudando a config.
Um lugar controla TUDO:
# Config global (válida para TODO o programa DSPy)
dspy.settings.configure(
lm=dspy.OpenAI(model='gpt-4o-mini'), # LM principal
rm=dspy.FaissRM( # Retriever para RAG
embedding_model=dspy.OpenAI(model='text-embedding-3-small')
),
cache=False, # Cache de chamadas
temperature=0.7 # Criatividade
)
# Agora TODO programa usa essa config automaticamente
program1 = ChainOfThought(signature)
program2 = MIPROv2(metric)
# Ambos usam GPT-4o-mini + Faiss automaticamente
Lista de LMs Suportados (2026):
Remotos:
- OpenAI: gpt-4o, gpt-4o-mini
- Anthropic: claude-3.5-sonnet
- Google: gemini-2.0-pro
- Mistral: mistral-large
Locais:
- Ollama: llama3.2, phi3, gemma2
- SGLang: serve qualquer modelo local
- vLLM: alta performance local
Aplicações Práticas e Estudos de Caso:
RAG (Geração Aumentada de Recuperação): Construção de pipelines de busca e resposta otimizáveis.
Raciocínio Multi-hop: O uso do módulo SimplifiedBaleen para tarefas complexas que exigem múltiplas etapas de busca.
Text-to-SQL e Classificação: Exemplos de como o DSPy lida com extração de dados estruturados e tarefas de negócios como análise de NPS.
Asserções e Sugestões (Assertions & Suggestions): Imposição de restrições computacionais em tempo de execução com mecanismos de backtracking (retrocesso).
Módulo Refine: O sucessor das asserções para o auto-refinamento iterativo de saídas baseado em feedback.
Um exemplo que gosto muito que é o Text-to-SQL:
import dspy
import sqlite3
from typing import List
# Configuração (troque pela sua API)
dspy.settings.configure(lm=dspy.OpenAI(model='gpt-4o-mini'))
# Schema do banco (exemplo e-commerce)
SCHEMA = """
Tabelas:
- products: id, name, price, category, stock
- orders: id, product_id, customer_id, quantity, order_date
- customers: id, name, email, city
"""
class TextToSQLSignature(dspy.Signature):
"""Gera SQL válido para consulta de banco de dados.
Schema das tabelas: {SCHEMA}
Use apenas SELECT, WHERE, JOIN, GROUP BY, ORDER BY.
"""
question: str = dspy.InputField(desc="Pergunta em linguagem natural")
sql_query: str = dspy.OutputField(desc="SQL válido e otimizado")
class SQLExecutor(dspy.Module):
def __init__(self):
super().__init__()
self.generator = dspy.ChainOfThought(TextToSQLSignature)
def forward(self, question: str, conn: sqlite3.Connection) -> dspy.Prediction:
# Gera SQL
sql_pred = self.generator(question=question)
sql = sql_pred.sql_query.strip()
try:
# Executa e pega resultados
cursor = conn.execute(sql)
results = cursor.fetchall()
columns = [desc[0] for desc in cursor.description]
return dspy.Prediction(
sql_query=sql,
results=results,
columns=columns,
error=None
)
except Exception as e:
return dspy.Prediction(
sql_query=sql,
results=[],
columns=[],
error=str(e)
)
Repare que no contrato (Signature) eu especifico apenas o que vai entrar e a saida esperada e ele se encarrega no do prompt:
question: str = dspy.InputField(desc="Pergunta em linguagem natural")
sql_query: str = dspy.OutputField(desc="SQL válido e otimizado")
Melhores práticas para dividir datasets no Dspy:
As melhores práticas para dividir datasets no DSPy seguem uma lógica de engenharia de software rigorosa, adaptada para a natureza estocástica dos modelos de linguagem. Diferente do aprendizado profundo tradicional, o DSPy permite começar com volumes muito pequenos de dados, mas exige separação cuidadosa para garantir a generalização (ou modularização que mencionei anteriormente).
1. Separação Rigorosa de Conjuntos
É fundamental manter conjuntos distintos para evitar o overfitting (ajuste excessivo) dos prompts aos exemplos de treino. As fontes sugerem três divisões principais:
- Trainset: Usado pelos otimizadores para realizar o bootstrapping (geração automática de exemplos de raciocínio) e ajustar as instruções.
- Devset (ou Valset): Utilizado durante o processo de compilação por algoritmos de busca (como o Random Search) para selecionar qual versão do programa obteve a melhor pontuação na métrica.
- Testset: Reservado exclusivamente para a validação final, garantindo que as melhorias obtidas durante a otimização funcionem em dados nunca vistos pelo compilado.
class SentimentMiproManager:
def __init__(self, train_size=0.8):
full_dataset = sentiment_dataset_train()
self.base_program = SentimentClassifier()
if not full_dataset:
print("Erro: Dataset vazio!")
return
# --- SEÇÃO DE SEPARAÇÃO (SPLIT) ---
random.seed(42)
random.shuffle(full_dataset)
split_idx = int(len(full_dataset) * train_size)
self.trainset = full_dataset[:split_idx] # Usado para compilar/otimizar
self.testset = full_dataset[split_idx:] # Usado para avaliação final
print(f"Dataset carregado: {len(self.trainset)} treino / {len(self.testset)} tese")
Tópicos avançados do MiProV2:
O MIPROv2 (Multi-prompt Instruction PRoposals Optimizer Version 2) é um dos otimizadores mais robustos do DSPy, projetado para sistemas de larga escala onde a precisão máxima é essencial. Ele se diferencia por ser “data-aware” (sensível aos dados) e “demonstration-aware” (sensível às demonstrações), otimizando simultaneamente as instruções em linguagem natural e os exemplos few-shot para cada módulo do programa.
1. Para que serve?
O MIPROv2 serve para substituir o ajuste manual de prompts por um processo de otimização matemática. Ele é ideal para:
- Sistemas de produção onde cada ganho percentual de acurácia é valioso.
- Cenários com conjuntos de dados moderados a grandes (ex: mais de 200 exemplos para evitar overfitting).
- Situações onde o desenvolvedor deseja que o framework encontre as melhores instruções e os melhores exemplos de uma só vez.
2. Funcionamento Interno
O MIPROv2 opera através de um ciclo de três estágios principais:
1. Estágio de Bootstrapping (Inicialização):
O otimizador executa o programa em várias entradas do conjunto de treino para coletar traços (traces) de comportamento de entrada e saída. Ele filtra esses traços, mantendo apenas aqueles que resultaram em pontuações altas de acordo com a métrica definida.
2. Estágio de Proposta Fundamentada (Grounded Proposal):
O MIPROv2 analisa o código do programa, os dados e os traços coletados para redigir múltiplas variações de instruções para cada prompt individual no pipeline.
3. Estágio de Busca Discreta (Discrete Search):
Utiliza Otimização Bayesiana para explorar o espaço de busca. Ele amostra minibatches do treino para avaliar combinações de instruções e traços. Um modelo substituto (surrogate model) probabilístico é atualizado com os resultados, prevendo quais direções de busca são mais promissoras através de uma função de aquisição chamada Expected Improvement (EI).
3. Parâmetros Avançados:
O MIPROv2 permite um controle fino sobre o orçamento computacional e a estratégia de busca através dos seguintes parâmetros:
- auto: Define configurações automáticas de hiperparâmetros. Pode ser “light” (rápido e barato), “medium” ou “heavy” (busca exaustiva).
- metric: A função Python que avalia a saída e guia a otimização.
- max_bootstrapped_demos: Define o número máximo de exemplos gerados automaticamente pelo “professor” a serem incluídos no prompt.
- max_labeled_demos: Define o número máximo de exemplos do conjunto de treino (com rótulos reais) a serem incluídos no prompt.
- minibatch_size: Tamanho do lote de dados usado em cada etapa da busca discreta para acelerar a avaliação.
- num_threads: Número de threads para processamento paralelo durante a compilação.
- prompt_model: O modelo de linguagem específico encarregado de gerar as propostas de novas instruções.
- teacher_settings: Configurações de LM para o programa “professor” que gera os traços iniciais durante o bootstrapping.
Em termos de resultados práticos, o uso do MIPROv2 em modo light elevou a acurácia de agentes ReAct de 24% para 51% e de sistemas de classificação de 62% para 82%.
Conclusão
O objetivo deste artigo foi, acima de tudo, despertar a sua curiosidade sobre como o DSPy está transformando o processo artesanal de “prompt engineering” em uma disciplina de engenharia de software rigorosa e sistemática. Ao longo desta exploração, vimos que a fascinante ideia central da biblioteca é tratar modelos de linguagem como funções parametrizadas dentro de um grafo computacional, permitindo que o comportamento do sistema seja definido por código estruturado em vez de strings frágeis.
Essa mudança de paradigma permite que os desenvolvedores se concentrem na lógica declarativa por meio de assinaturas e módulos reutilizáveis, delegando ao compilador do DSPy a tarefa de gerar instruções e exemplos otimizados para maximizar métricas específicas. Seja na construção de sistemas RAG robustos ou no desenvolvimento de agentes complexos, o framework oferece uma base para criar software de IA que é portátil entre diferentes modelos, confiável e capaz de se auto-aperfeiçoar com base em dados.
Esperamos ter demonstrado que a era das “tentativas e erros” manuais em prompts está sendo superada por um futuro onde a programação sistemática de modelos de fundação é o novo padrão para a inteligência artificial. O DSPy não é apenas uma ferramenta, mas um convite para reimaginar como construímos sistemas inteligentes de forma escalável e mensurável.
Convido você a dar uma Star e seguir meu projeto de aprendizado do Dsypy:
Bebam agua, se exercitem e obrigado!